
Исследователи из Facebook AI разрабатывают новый алгоритм обучения с подкреплением под названием DD-PPO. Он может перемещаться по сложным средам, используя только данные компаса, RGB-D камеру и GPS.
Разработка интеллектуальных машин, которые умно взаимодействуют с физическим миром, была долгосрочной целью сообщества ИИ. Главная задача состоит в том, чтобы научить эти машины так, чтобы они могли эффективно перемещаться по сложной, незнакомой среде без использования какой-либо карты.
Как правило, карты реального мира устаревают в течение нескольких месяцев, поскольку здания и сооружения меняются, а объекты перемещаются. Вот почему совершенно необходимо создать ИИ для физического мира, который может перемещаться без карты.
Помня об этом, исследователи из Facebook AI разработали новый алгоритм обучения с подкреплением (RL), который эффективно решает задачу точечной навигации с использованием только данных компаса, камеры RGB-D и GPS. Этот крупномасштабный алгоритм называется DD-PPO (децентрализованная распределенная проксимальная оптимизация политики).
В настоящее время системы, основанные на машинном обучении, способны превзойти человеческих экспертов в различных сложных играх. Но поскольку эти системы опираются на огромный объем обучающих выборок, то их построение без масштабного, распределенного распараллеливания совершенно невозможно.
Современная распределенная архитектура обучения с усилением – включает в себя тысячи рабочих (ЦП) и сервер с одним параметром – плохо масштабируется. Вот почему исследователи предложили синхронную, распределенную технику обучения с подкреплением.
DD-PPO работает на нескольких машинах и не имеет сервера параметров. Каждый работник (ЦП) переключается между накоплением опыта в моделируемом окружении с ускорением на GPU и оптимизацией модели. В явном состоянии связи все работники синхронизируют свои обновления с моделью. Другими словами, распределение является синхронным.
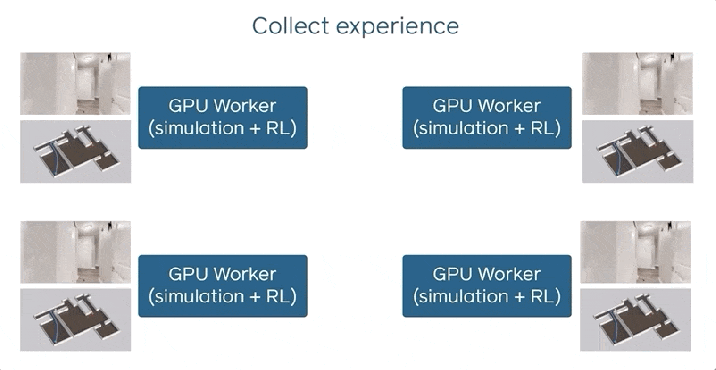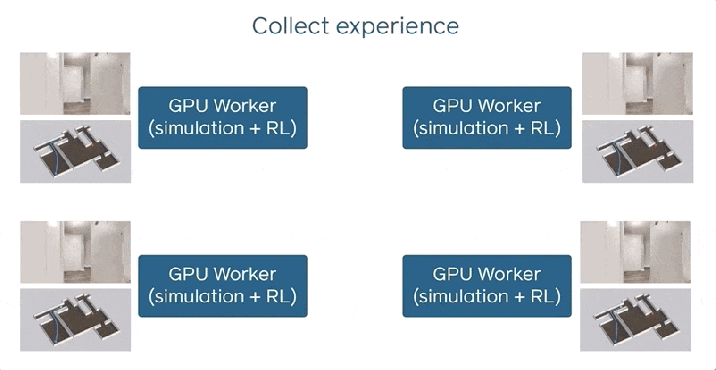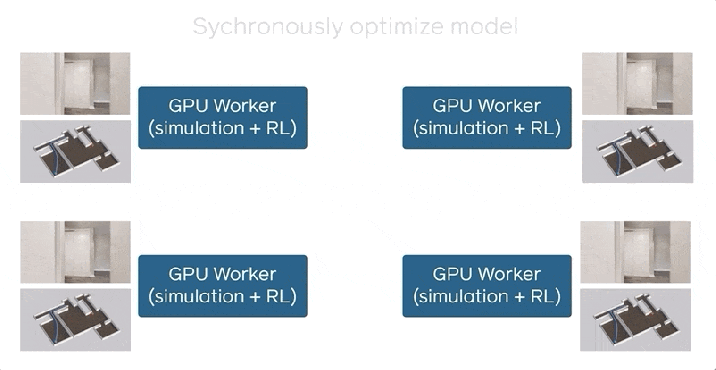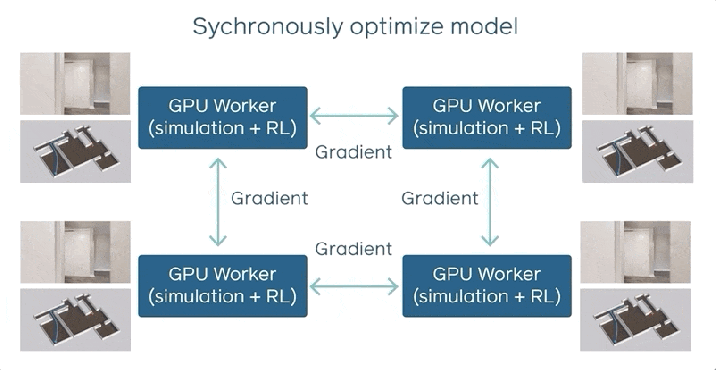
Используя этот подход, DD-PPO продемонстрировал почти линейное масштабирование: ему удалось добиться ускорения в 107 раз на 128 графических процессорах по сравнению с последовательной реализацией.
При навигации по точке-цели агент устанавливается в произвольном начальном положении / ориентации в незнакомой среде и получает задание перейти к целевым координатам без использования какой-либо карты. Он может использовать только компас, GPS и либо RGB или RGB-D камеры.
Исследователи использовали функцию масштабирования DD-PPO для обучения агента за 2,5 миллиарда шагов, что эквивалентно 80-летнему опыту человека. Вместо месяцев обучение было завершено менее чем за три дня с 64 графическими процессорами.
Результаты показали, что 90% пиковой производительности были получены в первые 100 миллионов шагов с меньшим количеством вычислительных ресурсов (8 графических процессоров). С миллиардами шагов опыта, агент достигает успеха 99,9%. Напротив, предыдущие системы достигли 92% успеха.

Эти агенты ИИ могут помочь людям в физическом мире. Например, они могут показывать соответствующую информацию пользователям, носящим очки дополненной реальности, роботы могут извлекать предметы со стола наверху, а системы искусственного интеллекта могут помочь людям с нарушениями зрения.
Модели, построенные в этом исследовании, могут работать в обычных условиях, таких как внутри лабораторий и офисных зданий, где дополнительные точки данных (карты и данные GPS) недоступны.
Несмотря на то, что модель ImageNet превосходит предварительно обученные сверхточные нейронные сети и может служить универсальным ресурсом, предстоит еще многое сделать для разработки систем, которые учатся ориентироваться в сложных средах. Исследователи в настоящее время изучают новые подходы к реализации точечной навигации по RGB.